Carga Inicial
Para poder desplegar la aplicación se debe realizar un carga inicial de datos hasta una fecha indicada. El objetivo es construir los cubos de Kylin a los que la aplicación va a realizar consultas. Esta carga inicial se realiza por medio de scripts en Python, versión 2.x, de un paquete llamado ETL_Processes.
Configurar Archivo de Parametros
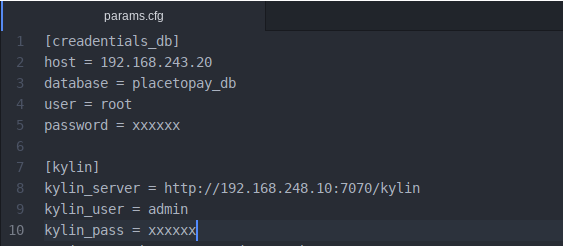
Dentro del paquete se encuetra un archivo de parámetros llamado _params.cfg. _En este archivo los valores que se deben configurar son aquellos que indican los accesos a la base datos de MySQL, al servidor de Kylin y los que definen la manera como se hará la carga incremental. Para editar este archivo se puede hacer desde cualquier editor, por ejemplo _nano.
- Se deben ingresar los datos de acceso a la base de datos de MySQL y al servidor de Kylin. La configuración debe verse así:
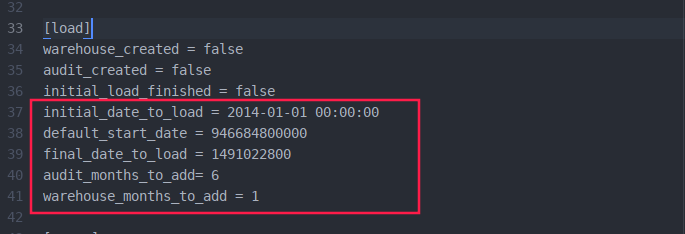
- La carga inicial se realiza de manera incremental para que el proceso no sea tan demandantes en los recursos de la máquina desde donde se haga. Los siguientes son los parámetros, dentro de la sección load, indican la forma como esta carga se realizará:
- initial_date_to_load: indica la fecha hasta donde se desea cargar datos en la primera iteración de la carga. Su formato debe ser YYYY-mm-dd HH:MM:SS.
- default_start_date: indica la fecha desde donde se desea cargar datos en la primera iteración de la carga. Su formato debe ser un Timestamp en milisegundos.
- final_date_to_load: indica la fecha que se utiliza como condición de parada para las iteración en la carga. Su formato debe ser un Timestamp en segundos.
- audit_months_to_add: _indica la cantidad de meses que se van a añadir en cada iteracion para el cubo _p2p_session_audit_cube.
- warehouse_months_to_add: indica la cantidad de meses que se van a añadir en cada iteración para el cubo p2p_data_warehouse_cube. Dado que las tablas en la base de datos en MySQL de las que se parte contienen muchos datos, se debe tener cuidado de no configurar muchos meses.
Una configuración para estos parámetros se vería así:
3.
Ejecución
- El paquete debe ser enviado al servidor donde se tenga instalado los servicios de Cloudera. En este caso se hara por medio de ssh:
$ scp ETL_Processes <usuario>@<ip-servidor>:<ubicacion> - En el servidor de Clodera se debe ingresar a la carpeta del paquete:
$ cd ETL_Processes - Ejecutar el script carga_incremental.pyI. Se debe ejecutar con permisos de super usuario, indicar que se corra en background, asegurar que el proceso corrar hasta que termine o alguna eventualidad ocurra y llevar las salidas del proceso a un log:
$ nohup sudo python2 carga_incremental > log/carga_incremental.log 2>&1 & - El log del proceso se puede monitoriar de la siguiente manera:
$ tail -f log/carga_incremental.log En cada iteración, la primera fase es la carga de datos desde MySQL a Hive. Cuando se empice a cargar los datos a Hive se lanza un trabajo de Hadoop y este se puede monitoriar gráficamente mediante el servicio HUE de Cloudera. Para esto se ingresa, desde un browser, a la siguiente dirección:
<direccion-servidor-cloudera>:8888
Se ingresa el usuario y la contraseña para autenticarse. Aparecerá la siguiente página:

Dar clic en botón Job Browser de la parte superior derecha:
- Aparecera la siguiente página:
- Del cuadro de texto username borrar el valor que aparece:

- Se mostrarán todos los procesos corridos y los que estan corriendo:
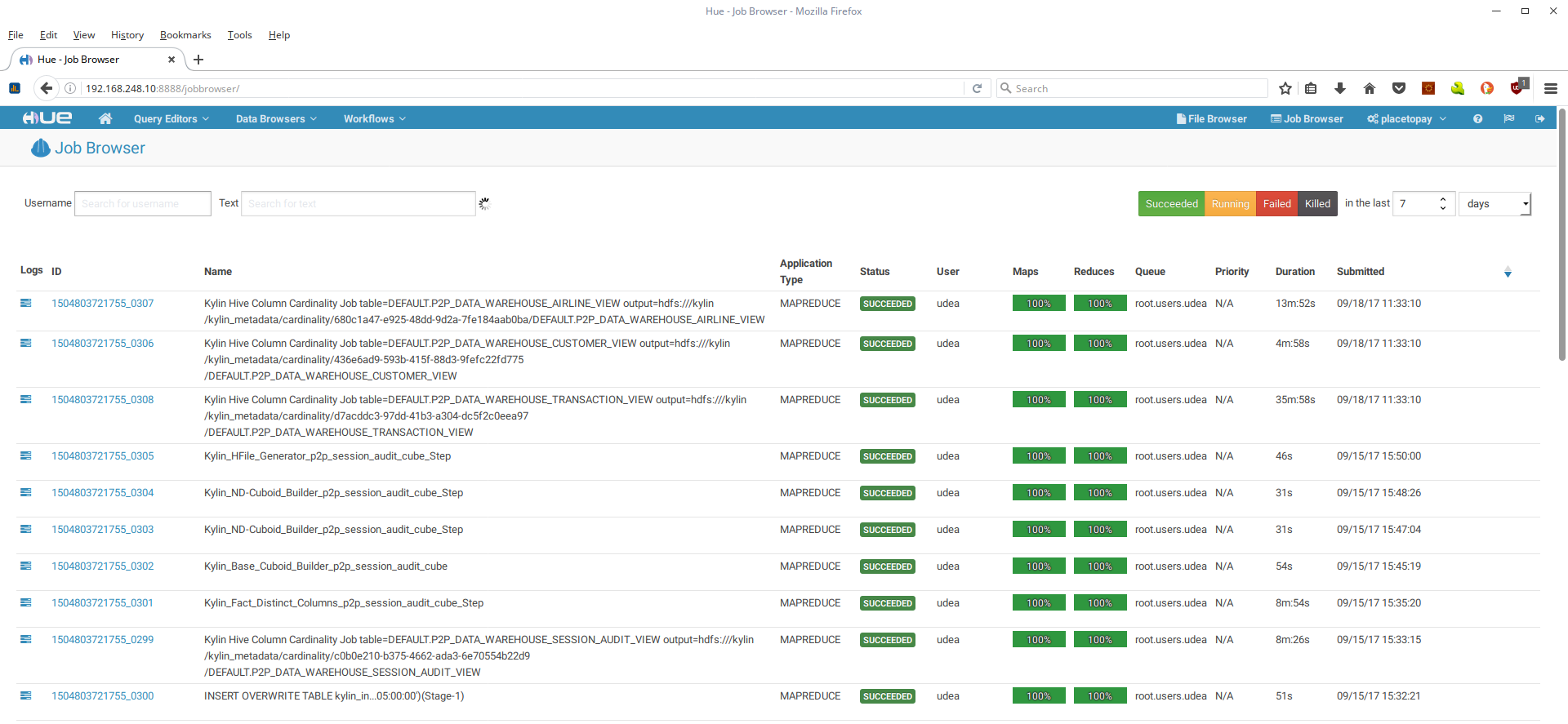
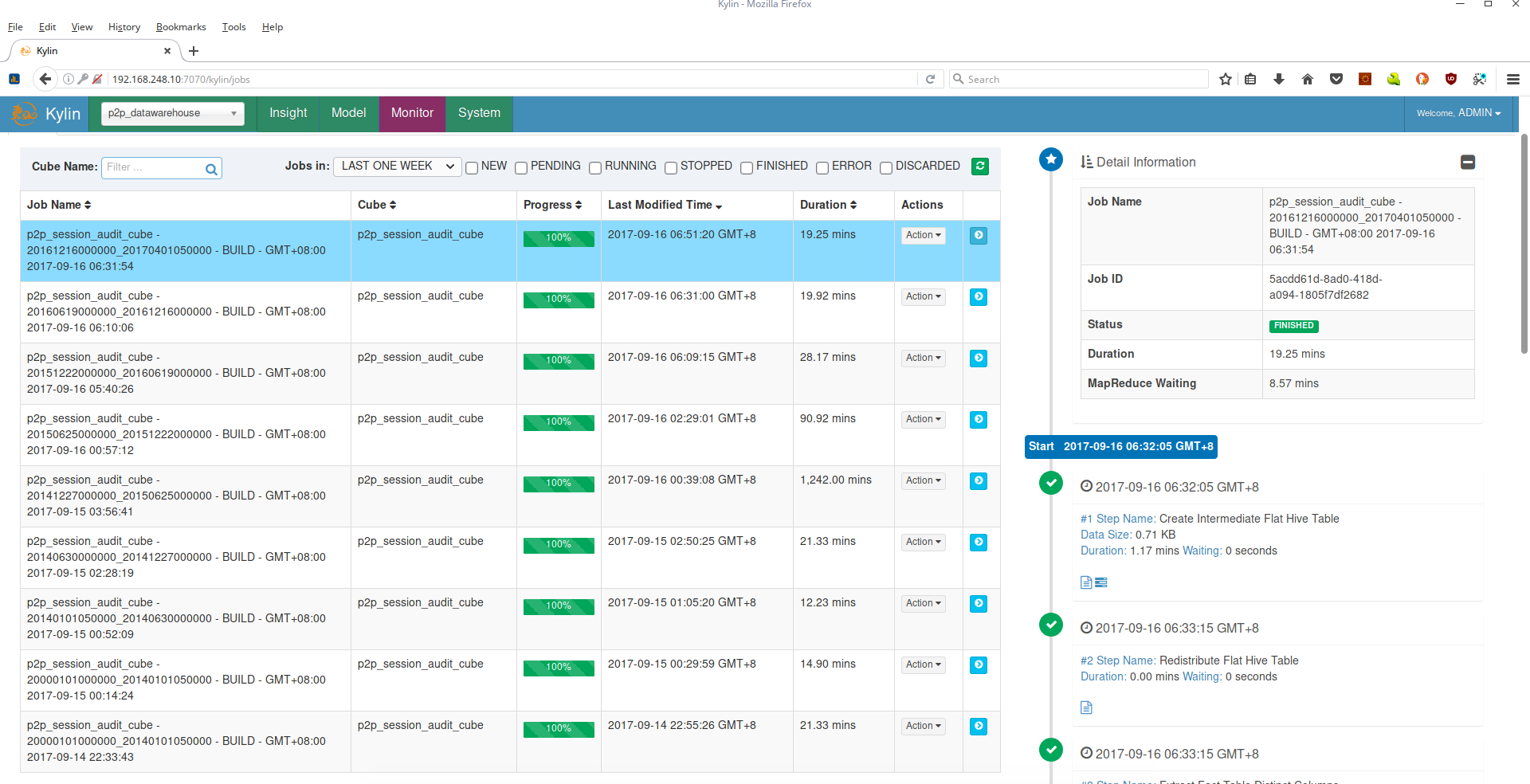
Una vez se carguen las tablas en Hive se empieza el proceso de la carga de datos a los cubos de Kylin. Para monitoriar este proceso se ingresa al servicio web de Kylin, como se indica al final del capítulo Instalación Kylin. Se debe seleccionar el proyecto p2p_datawarehouse:

Dar clic en el botón Monitor:

Se mostrará la lista de todos los procesos de carga de datos corridos y los que estan corriendo:
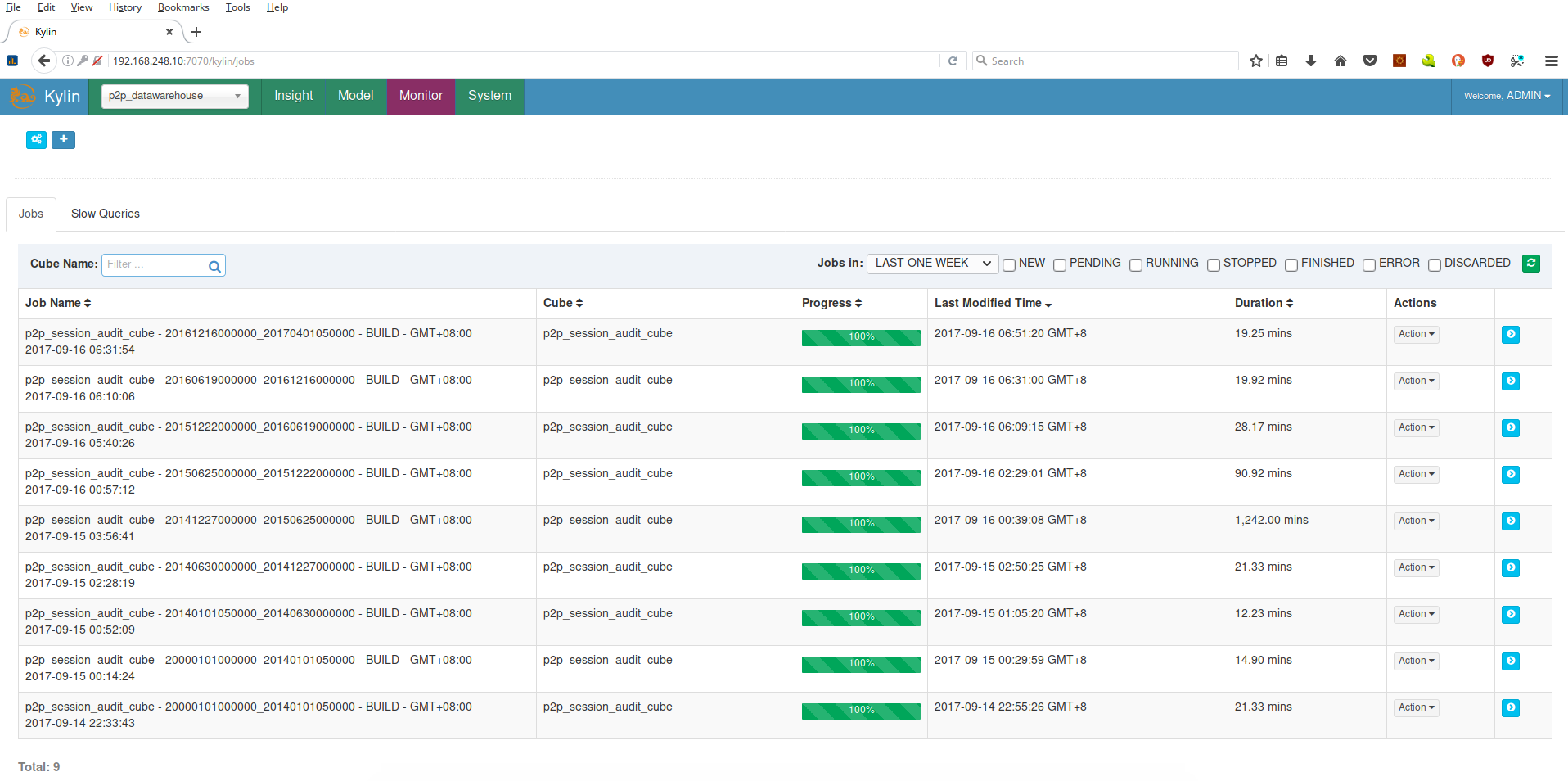
Para ver el paso en el que esta un proceso se da clic en la feche azul correspondiente:

Se listará información específica del proceso: